What I learned from making 200 different LLMs flip coins
TL;DR: LLMs finetuned for roleplaying give fair coin flips when prompted to do so. The best models for coding and problem solving give very biased coin flips. Factors like architecture and reasoning mode don’t explain much. Code to reproduce this work is provided on Colab.
Language models have no reason to flip coins. They are (broadly speaking) not capable of generating random numbers nor should they be able to do so - there’s no step in the data or training pipelines for LLMs that encourages this behavior.
But, what if they could? What would it take to produce an LLM capable of drawing a dozen numbers from a simple distribution with statistically reliable results?
The point isn’t to see whether \(\mathcal{M}_{transformers}\) is sufficiently expressive to implement a decent random number generator (surprise, it is) but rather to see if our best computational model for intelligence can be pushed to do it, and if it offers any benefits.
Towards this end, I wanted to see what happened if I used a simple prompt for simulating a coin flip with as many models as possible.
I acknowledge this is a dumb question. Here is a chance for you to cease reading and go about your day without any ill feelings from me.
Flipping coins across all of OpenRouter
OpenRouter supports over 200 large language models’ inference endpoints. Most of them support text and are tuned for instruction-following and chat. There’s a delightful range of models including the tried-and-true gpt-4-turbo, the roleplaying models, the foreign-language finetunes like scb10x/llama-3-typhoon-v1.5x-70b-instruct, and even cutting-edge diffusion models from like mercury/inception.
I wrote a Python notebook to run API calls against each of them using a simple prompt borrowed from a paper on prompting for rejection sampling for flipping coins:
prompt = '''
** Descriptions: ** Your task is to generate a sample consisting of a single draw from the set {0, 1},
where both 0 and 1 have a probability of 0.5. Please give your output strictly in the following format:
<format>
Explanations: [Your step-by-step analyses and results;
You DO NOT have access to a computer or a random number generator]
Output: [Your output MUST be an integer in {0, 1}]
</format>
Please ONLY reply according to this format, don't give me any other words.
Write the output EXACTLY like "Output: 0" or "Output: 1". Make sure to include the "Output: " prefix.
'''
Now, there are some problems with this prompt. Ideally, we’d replace 0 and 1 with randomly generated strings and marginalize over both orderings. This would be more work, so I skipped it.
We would also use structured generation to force outputs into {0, 1}. I skipped the latter because not all endpoints support structured generation.
If you were to run a similar analysis, here’s a list of models I would skip:
models_to_skip = (
'eleutherai/llemma_7b',
'google/gemini-2.5-pro-preview-05-06',
'meta-llama/llama-3.1-405b', # Had some weird errors
'meta-llama/llama-guard-2-8b',
'meta-llama/llama-guard-3-8b',
'meta-llama/llama-guard-4-12b',
'mistralai/mistral-7b-instruct-v0.2',
'morph/morph-v3',
'morph/morph-v3-fast',
'morph/morph-v3-large',
'openai/gpt-4o-mini-search-preview-2025-03-11',
'openai/gpt-5', # Requires a key to access it via OpenRouter
'openai/o1-mini',
'openai/o1-pro',
'openai/o3-pro',
'openrouter/auto',
'perplexity/sonar-deep-research',
'qwen/qwq-32b-preview',
'switchpoint/router',
'x-ai/grok-vision-beta',
)
Some of these models cost too much to run (sonar-deep-research), others don’t support a standard chat API (morph-v3) while others are aggressively rate-limited or require additional login info (google and openai, respectively).
This leaves you with roughly 240 models. A quick random sample of their IDs shows frontier labs, big corpos like meta, as well as startups like liquid, ai21 and kimi. All told, I spent about 80 bucks with a few small test runs. A lot of that was due to me forgetting that sonar-deep-research was enabled and that is a very expensive API to run.
Here are some of the most expensive models to run:
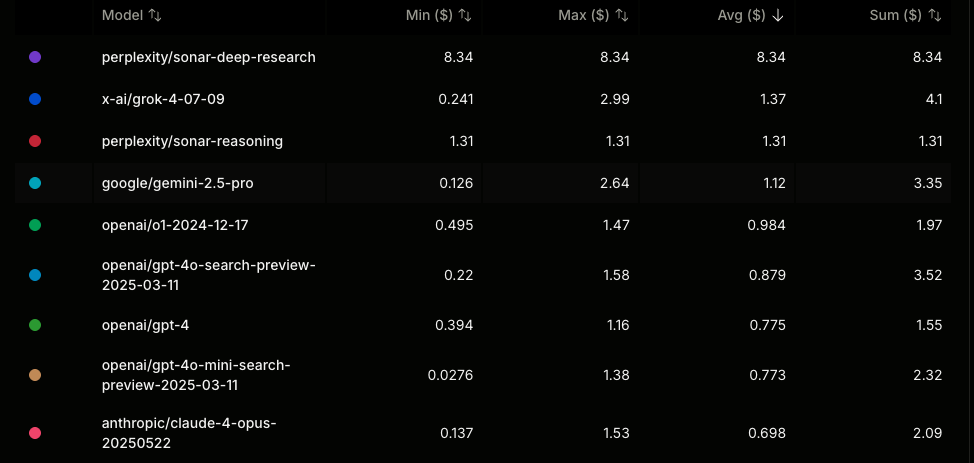
I was pleasantly surprised that I could get \(n\approx 50\) draws from each model for less than $40. I’d certainly like to do more cross-model experiments using OpenRouter.
Which models are biased the most?
I did a bunch of work on creating predictor features for each model using Perplexity’s API and a prompt like “Categorize model X as dense / mixture of experts and also determine if it uses reasoning…”. I used these as the covariates for a Bayesian binomial regression to see if there was a strong effect discernable from the data for aspects like model architecture, size, the organization that released it, etc.
Unfortunately, there weren’t any interesting findings. I tried with different parameterizations and likelihoods. The only effect I repeatedly found was that larger models tended to be less biased.
The actual results
I had a much better experience by just listing the models as ordered by their bias, defined as the absolute value of the average of their draws (confined to {0,1}) minus 0.5. In other words, it’s the distance of the sample mean from a fair coin flip’s \(p(heads)\). Smaller is better. Here are the 20 least biased models:
| Model Name | Bias |
|---|---|
| sao10k/l3.1-euryale-70b | 0.032 |
| inflection/inflection-3-pi | 0.032 |
| openai/gpt-4 | 0.024 |
| neversleep/noromaid-20b | 0.023 |
| mistralai/pixtral-large-2411 | 0.022 |
| sao10k/l3.3-euryale-70b | 0.022 |
| meta-llama/llama-4-maverick | 0.022 |
| qwen/qwen2.5-vl-32b-instruct | 0.022 |
| scb10x/llama3.1-typhoon2-70b-instruct | 0.011 |
| infermatic/mn-inferor-12b | 0.011 |
| qwen/qwen-2.5-72b-instruct | 0.011 |
| sophosympatheia/midnight-rose-70b | 0.011 |
| cohere/command-r-plus-08-2024 | 0.011 |
| google/gemini-2.5-pro | 0.0 |
| cohere/command-a | 0.0 |
| nvidia/llama-3.1-nemotron-70b-instruct | 0.0 |
| openai/gpt-4-1106-preview | 0.0 |
| qwen/qwq-32b | 0.0 |
| perplexity/r1-1776 | 0.0 |
| arliai/qwq-32b-arliai-rpr-v1 | 0.0 |
Something that stood out to me immediately was the multiple roleplaying finetunes, like infermatic/mn-inferor-12b, arliai/qwq-32b-arliai-rpr-v1 , and sao10k/l3.3-euryale-70b among others.
None of the RP models show up on the top 20 most-biased:
| Model Name | Bias |
|---|---|
| inception/mercury-coder | 0.50 |
| arcee-ai/spotlight | 0.50 |
| cohere/command | 0.50 |
| google/gemini-2.0-flash-001 | 0.50 |
| qwen/qwen-vl-plus | 0.50 |
| microsoft/phi-4-multimodal-instruct | 0.48 |
| anthropic/claude-3.5-sonnet-20240620 | 0.48 |
| inception/mercury | 0.46 |
| google/gemini-flash-1.5-8b | 0.46 |
| openai/gpt-4o-mini-search-preview | 0.46 |
| anthropic/claude-3.7-sonnet | 0.44 |
| google/gemini-2.5-flash | 0.44 |
| amazon/nova-lite-v1 | 0.39 |
| cohere/command-r | 0.39 |
| openai/gpt-5-mini | 0.37 |
| deepseek/deepseek-chat-v3-0324 | 0.37 |
| anthropic/claude-3.5-sonnet | 0.37 |
| qwen/qwen3-235b-a22b-thinking-2507 | 0.36 |
| meta-llama/llama-4-scout | 0.35 |
| anthropic/claude-opus-4.1 | 0.35 |
Here, we see many of the heavy-hitters from the last 18 months. The best Claude models are all represented here, as is deepseek-chat-v3-0324 and qwen3-235b-a22b-thinking-2507. The coding-specialized models fron Mercury also both show up here.
This hints at a connection between sampling reliability and creativity. The models which are clearly most tuned for coding/problem solving like Claude and Deepseek are also the worst at giving a balanced sample of coin flips. Conversely, models finetuned for creative and interesting dialogue tend to show less bias.
Enjoy Reading This Article?
Here are some more articles you might like to read next: